执行一条 SQL 的流程
本文最后更新于 2025年8月27日 16:04
概述
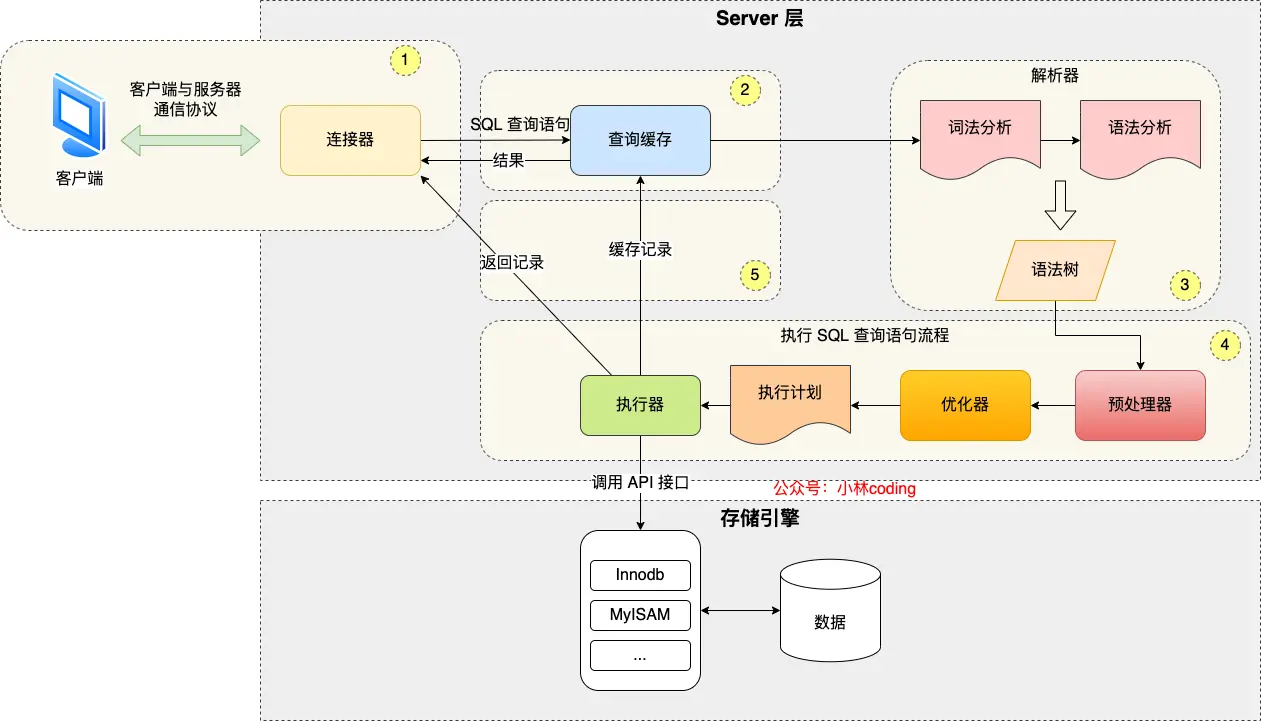
从图上可以看出 MySQL 其实分为了 Server 层和存储引擎层。Server 层负责建立连接、分析和执行 SQL;而存储引擎层负责数据的存储和提取。
一条 SQL 可以分为简单分为以下几个阶段:连接、查询缓存、解析 SQL 和执行 SQL。
连接
- 建立连接:客户端通过 IP、端口号、用户名、密码等信息,通过 TCP 协议连接到 MySQL Server。
- 管理连接:Linux 控制台中的连接为一个长连接,由于 MySQL 使用内存管理连接,所以长连接过多会导致内存占用过高,MySQL 进程可能会被系统杀掉。可以通过定时断开长连接或者客户端主动重置连接来解决长连接内存占用问题。在 Java 中一般是通过连接池(如 HikariCP)进行管理。
- 身份验证:MySQL 会校验用户的身份信息,并检查该用户是否有权限执行对应的 SQL 操作(例如是否有
SELECT权限)。
查询缓存(已在 MySQL 8.0 被移除)
缓存以 K-V 形式保存在内存中,key 为 SQL 语句,value 为查询结果。
MySQL 会先检查是否启用了查询缓存。如果命中缓存(即之前执行过相同的 SQL 且表未被修改),则直接从缓存中读取结果返回。如果没有命中,则进入 SQL 解析和执行流程。
功能鸡肋:如果生成了一个大缓存,但是还没有使用就更新了表中数据,该缓存会被直接清空。
解析 SQL
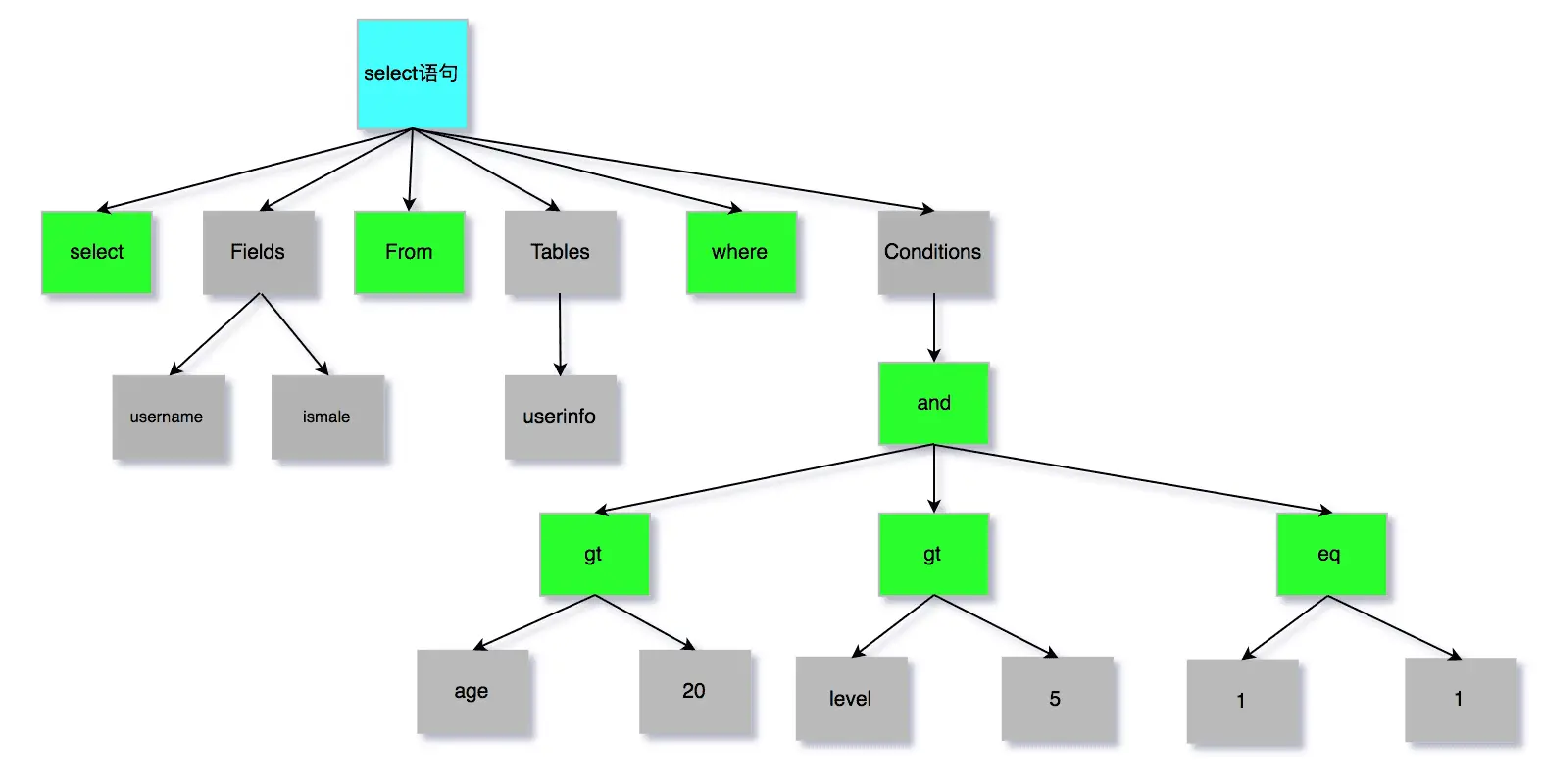
- 词法分析:从 SQL 语句中识别出关键字和非关键字
- 语法分析:将词法分析结果按语法规则组织成“语法树”
执行 SQL 阶段
预处理阶段
- 检查表、字段是否存在,权限是否充足。
- 通配符展开(将
*扩展为所有列)
优化阶段(优化器)
优化器主要负责确定 SQL 语句的执行方案。比如表中有多个索引时,优化器需要根据查询成本,确定使用哪个索引,我们可以通过 explain 指令查询 SQL 语句的执行计划。
在 explain 指令返回的信息中,我们重点关注的是以下几个指标:
type:表示连接类型,体现扫描效率,这是 SQL 语句的优化重点。常见值如下:
ALL:全表扫描 (最差)index:全索引扫描range:范围扫描(BETWEEN、<、>)ref:普通非唯一索引等值查询eq_ref:唯一索引等值(效率高)const/system:常量查询(最优)
目标是尽量避免
ALL,提升到ref或更优。possible_keys / key
possible_keys:可能用到的索引key:实际使用的索引
如果
possible_keys有值但key为空,说明优化器没走索引,需要检查条件是否合适。rows:表示 MySQL 预估需要扫描的行数(不是精确值),越小越好,说明索引命中效果好。
Extra:附加信息,能提示优化方向。常见值:
Using index:覆盖索引(好)Using where:需要回表Using temporary:用了临时表 (差)Using filesort:额外排序操作(差,优化重点)
执行阶段(执行器)
执行器主要负责与存储引擎以记录为单位进行交互。接下来以三个场景为例,梳理一下执行器和存储引擎交互的过程。
主键索引查询
1 | |
特点:主键唯一,等值查询;高效,直接定位一条记录,代价最小。
执行器流程:
- 执行器第一次调用存储引擎,用主键索引直接定位 B+ 树中 id=1 的记录。
- 如果记录存在,则返回给执行器;如果不存在则报错结束。
- 因为是 const 类型(只会有一条),第二次调用直接返回 -1,查询结束。
全表查询
1 | |
特点:name 没有索引;遍历全表逐条判断,代价高。
执行器流程:
- 第一次调用存储引擎,拿到第一条记录。
- Server 层判断是否符合条件(
name = iphone),符合则返回给客户端。 - 再次调用存储引擎,继续读下一条记录,判断是否满足条件,返回或跳过。
- 一直循环,直到所有记录读完。
索引下推 Index Condition Pushdown
1 | |
联合索引 (age, reward),但范围查询遇到 age > 20 时,reward 列就不能继续利用索引。
MySQL 5.6 之前(没有 ICP):
- 存储引擎找到
age > 20的索引记录,回表取整行交给 Server 判断reward = 100000。 - 存在问题:每条候选记录都要回表,IO 开销大。
MySQL 5.6 之后(有 ICP):
- 存储引擎在索引层就能顺便判断
reward = 100000,如果 reward 不匹配则直接丢掉,不回表;只有匹配的才回表。 - 好处:减少了回表次数,大幅提升效率。
- 执行计划里
Extra出现Using index condition,就说明用了索引下推。