线程池 ThreadPoolExecutor
本文最后更新于 2025年8月11日 14:57
什么是线程池
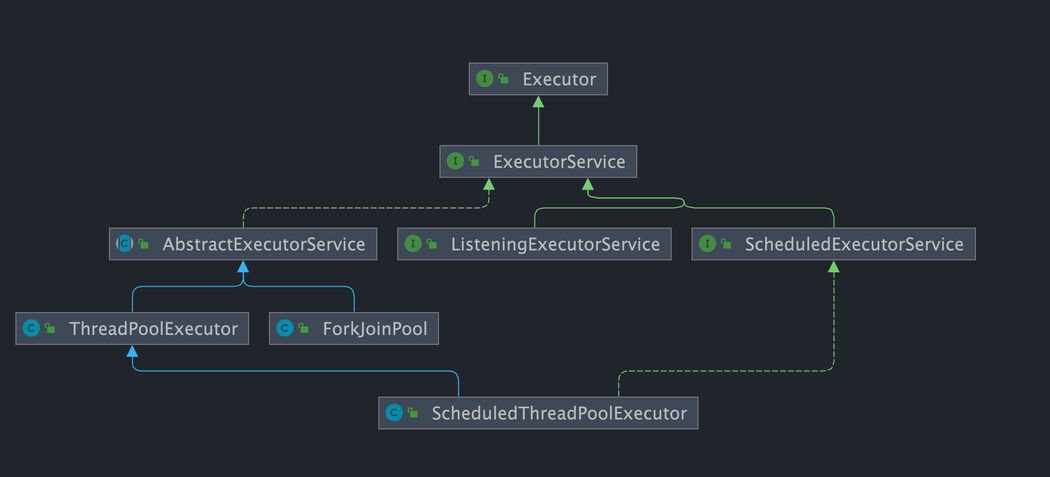
池化技术已经屡见不鲜了,线程池、数据库连接池、HTTP 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。线程池就是管理一系列线程的资源池,其提供了一种限制和管理线程资源的方式。
线程池一般用于执行多个不相关联的耗时任务,没有多线程的情况下,任务顺序执行,使用了线程池的话可让多个不相关联的任务同时执行,提高任务的执行效率,降低资源消耗,同时能够更好地管理线程资源。
线程池的整体设计
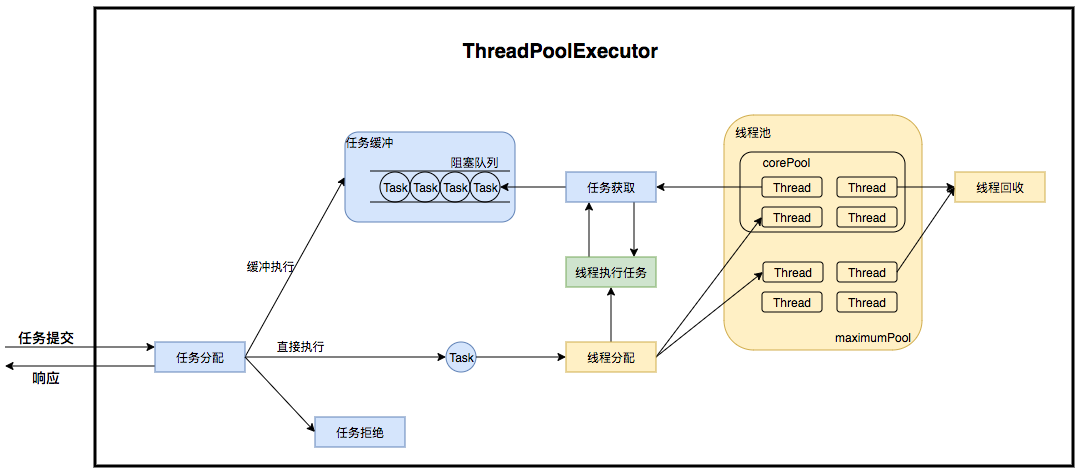
可以将整个线程池看做一个大型的生产者-消费者模型。我们将线程池分为 任务管理和线程管理 两个部分。任务管理是生产者,负责提交任务;任务提交后,由线程池负责任务的流转逻辑;线程管理是消费者,负责具体的任务处理。
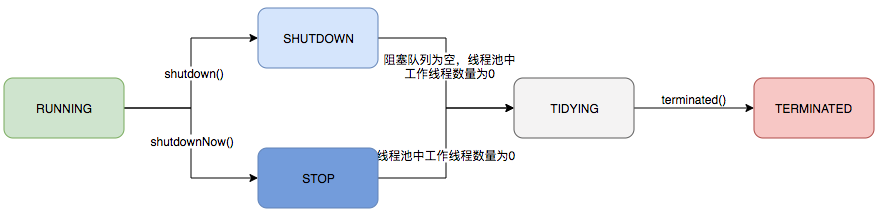
线程池的运行状态

任务管理
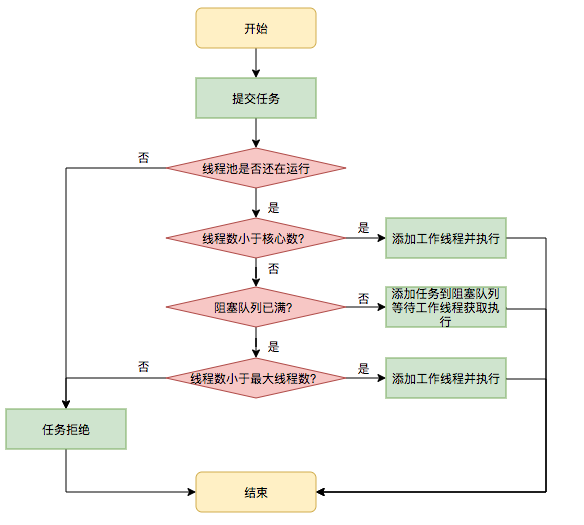
任务调度
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果 workerCount < corePoolSize ,则创建并启动一个线程来执行新提交的任务。
- 如果 workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果 workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果 workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满,,则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
任务缓冲
任务缓冲模块是线程池能够管理任务的核心部分。线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:
- 在队列为空时,获取元素的线程会等待队列变为非空。
- 当队列满时,存储元素的线程会等待队列可用。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
使用不同的队列可以实现不一样的任务存取策略。

任务拒绝
任务拒绝模块是线程池的保护部分。线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize 时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
拒绝策略是一个接口,其设计如下:
1 | |
用户可以通过实现接口来定制拒绝策略,也可以选择 JDK 提供的四种已有拒绝策略,其特点如下:
- AbortPolicy:任务不能再提交时直接抛出异常,线程池的默认拒绝策略。该策略适合于比较关键的业务,在并发量达到极限时及时抛出异常,使运维人员及时发现。
- DiscardPolicy:直接丢弃任务,不抛弃异常。该策略适合无关紧要的业务。
- DiscardOldestPolicy:丢弃任务队列中最前面的任务,然后重新提交被拒绝的任务。
- CallerRunsPolicy:由提交任务的线程处理该任务。这种策略适用于需要让所有任务都执行完毕的情况。
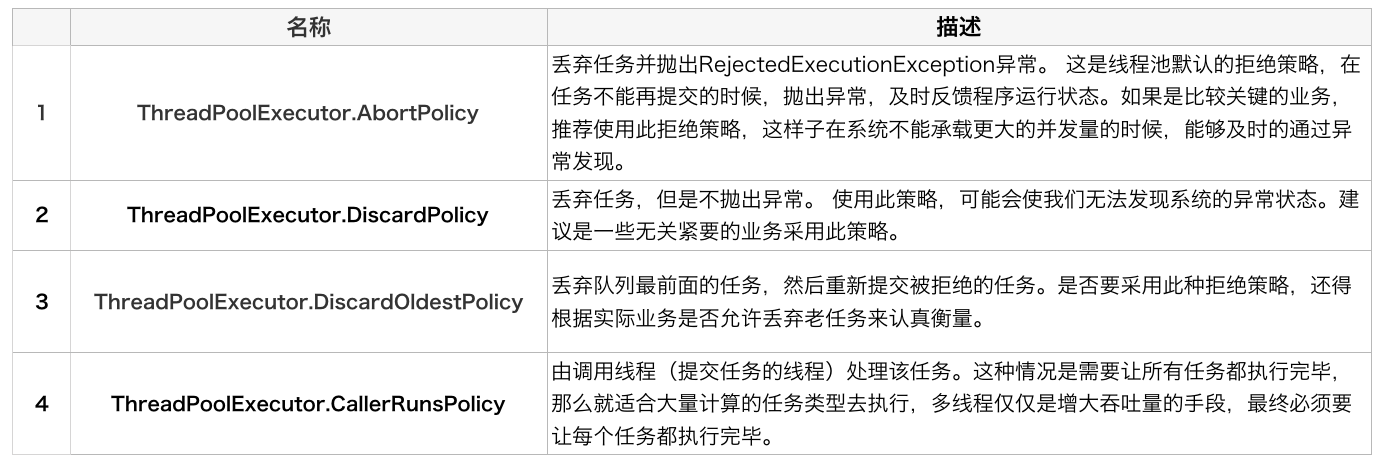
线程管理
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker。
1 | |
维护线程的生命周期
线程池使用一张 Hash 表去持有线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期,所以接下来要考虑的是如何判断线程是否在运行。Worker 通过继承 AQS,使用 AQS来实现独占锁这个功能。
锁状态的含义:
- 当 Worker 持有锁时(
lock()成功):表示线程正在执行任务 - 当 Worker 未持有锁时:表示线程处于空闲状态
如何判断空闲状态:
- 线程池在执行
shutdown方法或tryTerminate方法时,会调用interruptIdleWorkers方法来中断空闲的线程 - 调用
interruptIdleWorkers方法时,会尝试对每个 Worker 调用tryLock() - 如果
tryLock()成功,说明线程空闲(没有执行任务),可以安全中断 - 如果
tryLock()失败,说明线程正在执行任务,不应中断
线程增加
线程增加是通过线程池中的 addWorker 方法,该方法的功能就是增加一个线程,该方法不考虑线程池是在哪个阶段增加的该线程,这个增加线程的决策是在上个步骤完成的,该步骤仅仅完成增加线程的操作,并使它运行,最后返回是否成功这个结果。
线程回收
线程池中线程的销毁依赖 JVM 自动的回收,线程池做的工作是根据当前线程池的状态维护一定数量的线程引用,防止这部分线程被 JVM 回收,当线程池决定哪些线程需要回收时,只需要将其引用消除即可。
Worker 被创建出来后,就会不断地进行轮询,然后获取任务去执行,核心线程可以无限等待获取任务,非核心线程要限时获取任务。当 Worker 无法获取到任务,也就是获取的任务为空时,循环会结束,Worker 会主动消除自身在线程池内的引用。
线程池参数分析
ThreadPoolExecutor 3 个最重要的参数:
corePoolSize:任务队列中存放的任务未达到队列容量时,最大可以同时运行的线程数量。maximumPoolSize:任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue:新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
ThreadPoolExecutor其他参数 :
keepAliveTime:线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁。unit:keepAliveTime参数的时间单位。threadFactory:线程池创建线程时调用的工厂方法,通过此方法可以设置线程的优先级、线程命名规则以及线程类型(用户线程还是守护线程)等。handler:拒绝策略(默认使用的是AbortPolicy)
如何确定线程池参数
$$
N_{threads} = N_{cpu} \times U_{cpu} \times (1 + \frac{W}{C})
$$
其中,Ncpu = CPU的数量,Ucpu = 目标CPU的使用率( 0 <= Ucpu <= 1),W/C = 等待时间与计算时间的比率。
- 核心线程数:
- CPU 密集型任务:CPU 核心数 + 1(即使当 CPU 密集型的线程偶尔由于缺页其他原因而暂停时,这个“额外”的线程也能确保 CPU 的时钟周期不会被浪费。)
- IO 密集型任务:CPU 核心数 * 2(计算时间与等待时间相同)
创建一个线程池
第一种方式为直接通过 ThreadPoolExecutor 的构造函数进行创建。

第二种方式为通过 Executor 框架的工具类 Executors 来进行创建。
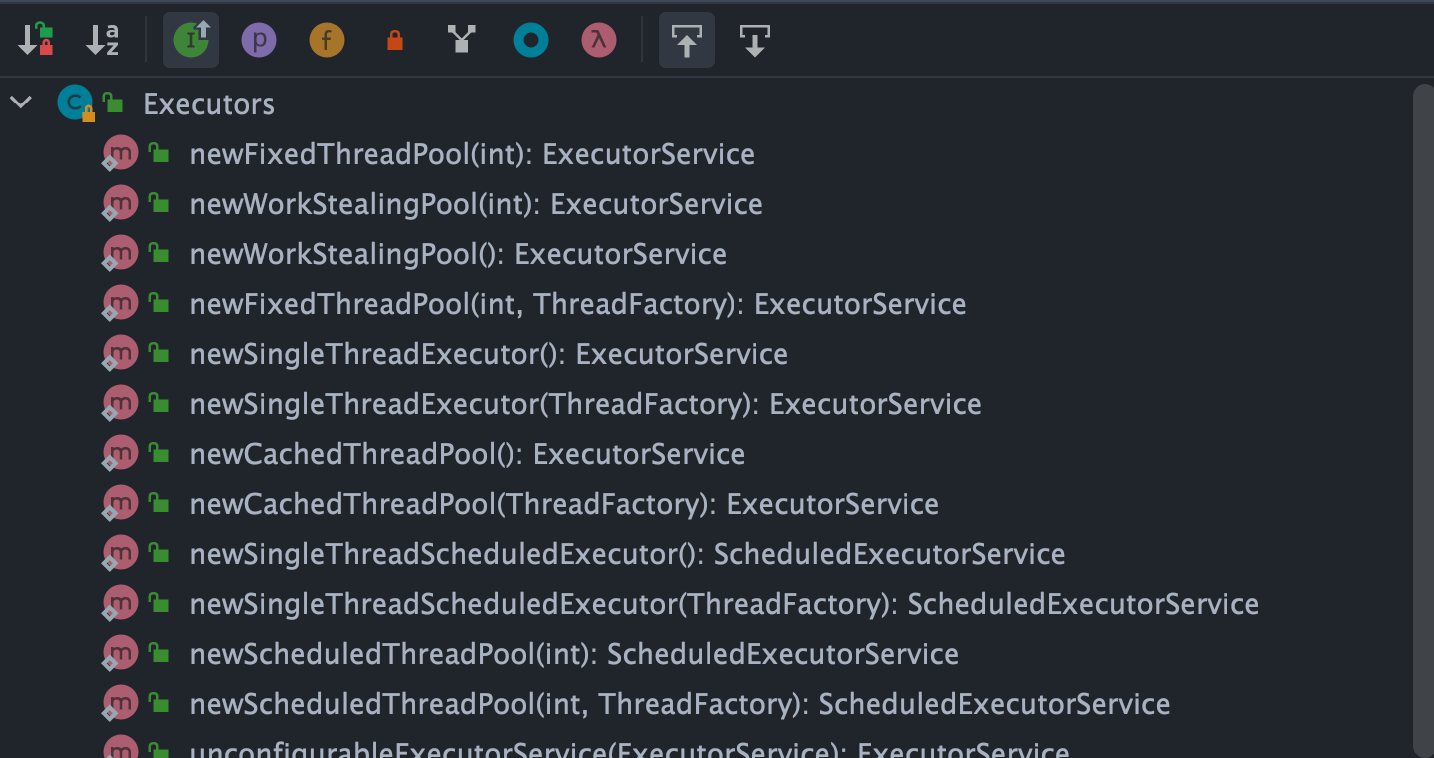
可以看出,通过Executors工具类可以创建多种类型的线程池,包括:
FixedThreadPool:固定线程数量的线程池。该线程池的核心线程数和最大线程数始终相等,都是在创建时固定的数量。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。SingleThreadExecutor: 只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。CachedThreadPool: 可根据实际情况调整线程数量的线程池。理论上,其最大线程数为Integer.MAX_VALUE,但实际受限于系统资源。若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。ScheduledThreadPool:在给定的延迟后运行任务,或定期执行任务的线程池。
《阿里巴巴 Java 开发手册》强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
Executors 返回线程池对象的弊端如下:
FixedThreadPool和SingleThreadExecutor:使用的是无界的LinkedBlockingQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。CachedThreadPool:使用的是同步队列SynchronousQueue, 允许创建的线程数量为Integer.MAX_VALUE,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。ScheduledThreadPool和SingleThreadScheduledExecutor:使用无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
线程池最佳实践
快速响应用户需求
比如用户需要查看某一个产品的信息,那么我们需要将产品维度的一切信息如定价、优惠、库存等等信息聚合后展示给用户。
从用户体验角度看,这个结果响应的越快越好,如果一个页面半天都刷不出,用户可能就放弃查看这个产品了。而面向用户的功能聚合通常非常复杂,伴随着调用与调用之间的级联、多级级联等情况,这时我们就可以选择使用线程池这种简单的方式,将调用封装成任务并行的执行,缩短总体响应时间。另外,使用线程池也是有考量的,这种场景最重要的就是获取最大的响应速度去满足用户,所以不应该设置队列去缓冲并发任务,而应该调高 corePoolSize 和 maxPoolSize 去尽可能创造多的线程快速执行任务。
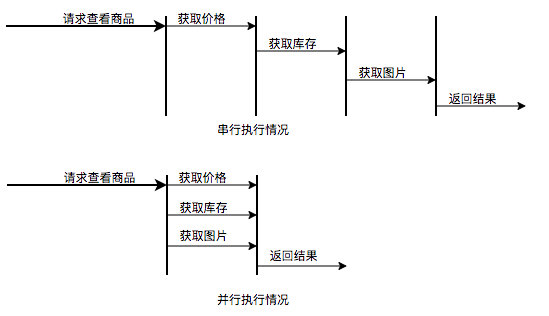
快速处理批量任务
离线的大量计算任务,需要快速执行。比如需要统计某个客户某个月的账单,用于后续出账或其他操作,那么我们就需要快速查询并生成报表。这种场景需要执行大量的任务,我们也会希望任务执行的越快越好。这种情况下,也应该使用多线程策略,并行计算。但与响应速度优先的场景区别在于,这类场景任务量巨大,并不需要瞬时的完成,而是关注如何使用有限的资源,尽可能在单位时间内处理更多的任务,也就是吞吐量优先的问题。所以应该设置队列去缓冲并发任务,调整合适的 corePoolSize 去设置处理任务的线程数。在这里,设置的线程数过多可能还会引发线程上下文切换频繁的问题,也会降低处理任务的速度,降低吞吐量。